32 Restructuring Data frames
We’ve already seen data frames with a couple of different structures, but we haven’t explicitly discussed those structures yet. When I say structure, I basically mean the way the data is organized into columns and rows. Traditionally, data are described as being organized in one of two ways:
- With a person-level, or wide, structure. In person-level data, each person (observational unit) has one observation (row) and a separate column contains data for each measurement. For example:
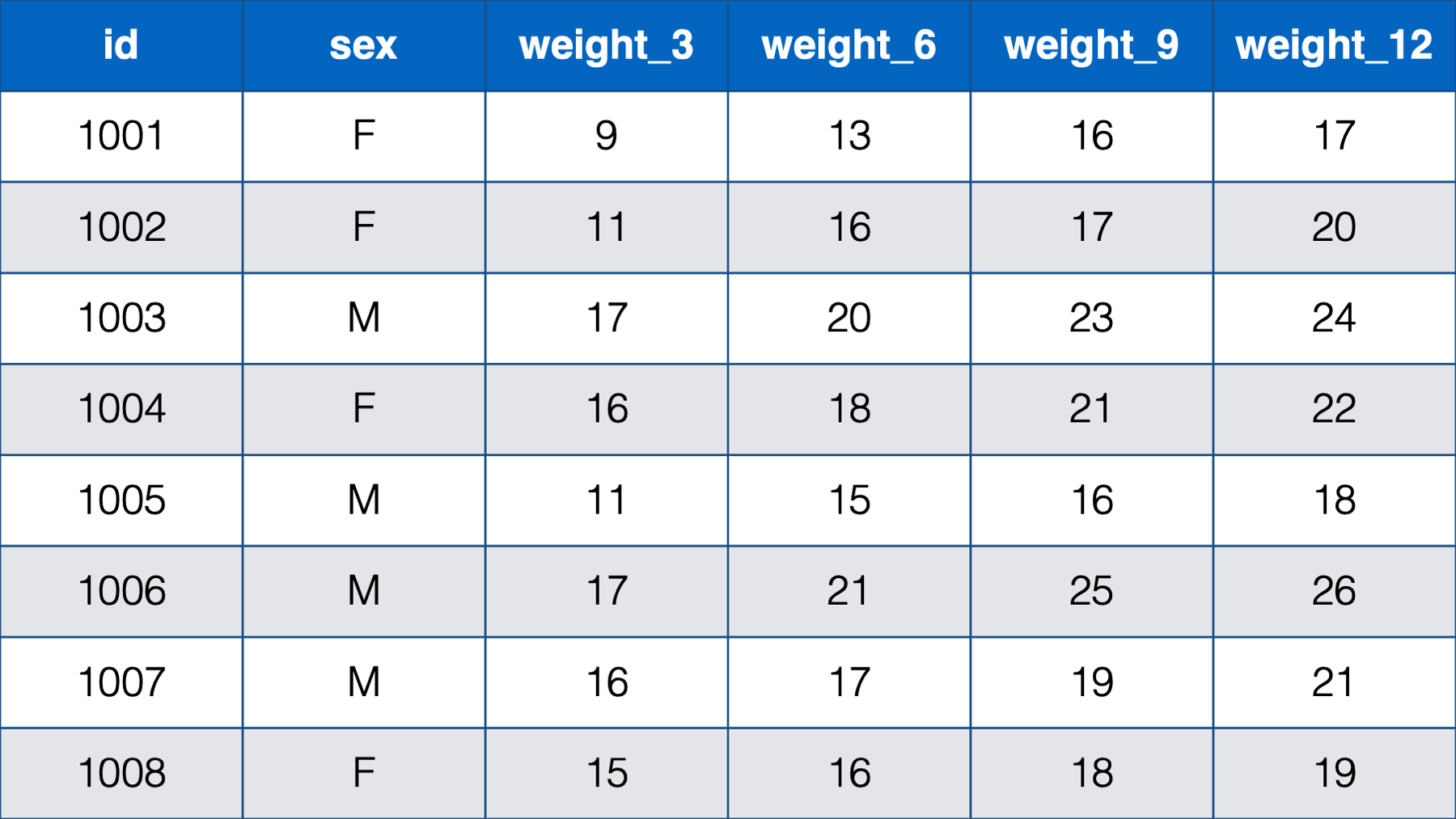
Figure 32.1: Baby weights at 3, 6, 9 , and 12 months.
- With a person-period, or long, structure. In the person-period data structure each person (observational unit) has multiple observations – one for each measurement occasion.
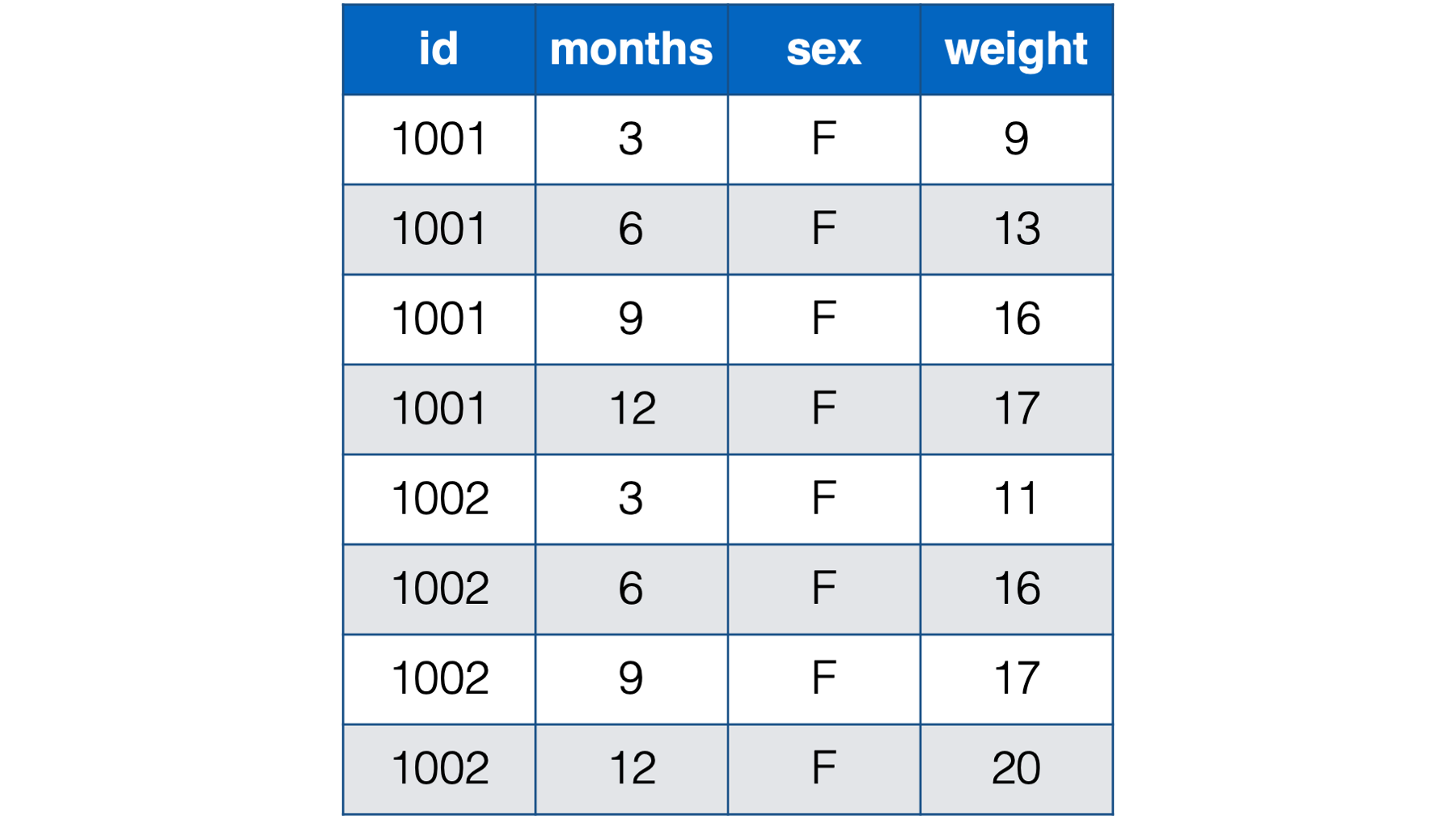
Figure 32.2: Baby weights at 3, 6, 9 , and 12 months. Babies 1001 and 1002 only.
🗒Side Note: Often, people are our observational unit in epidemiology. However, our observational units could also be schools, states, or air quality monitors. It’s the entity from which we are gathering data.
In some cases, only the person-level data structure will practically make sense. For example, the table below contains the sex, weight, length, head circumference, and abdominal circumference for eight newborn babies measured cross-sectionally (i.e., at one point in time) at birth.
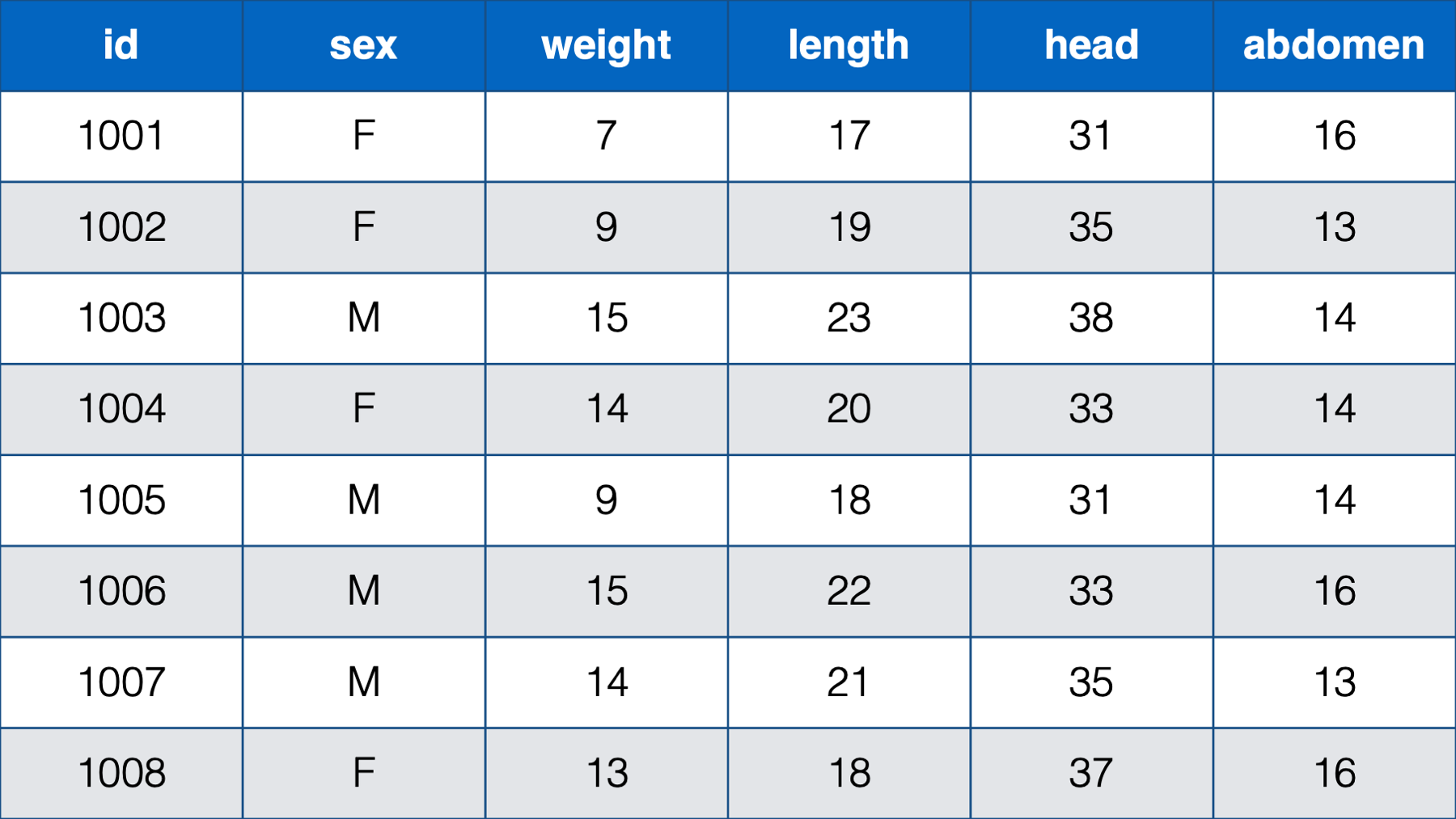
Figure 32.3: Various measurements take at birth for 8 newborn babies.
In this table, each baby has one observation (row) and a separate column contains data for each measurement. Further, each measurement is only taken on one occasion. There really is no other structure that makes sense for this data.
For contrast, the next table below is also person-level data. It contains the weight in pounds for eight babies at ages 3 months, 6 months, 9 months, and 12 months.
Figure 32.4: Baby weights at 3, 6, 9 , and 12 months
Notice that each baby still has one, and only one, row. This time, however, there are only 2 measurements – sex and weight. Sex is measured on one occasion, but weight is measured on four occasions, and a new column is created in the data frame for each subsequent measure of weight. So, although each baby has a single row in the data, they really have four observations (i.e., measurement occasions). Notice that this is the first time that we’ve explicitly drawn a distinction between a row and an observation. Further, unlike the first table we saw, this table could actually be structured in a different way.
An alternative, and often preferable, data structure for data with repeated measures is the person-period, or long, data structure. Below, we look at the baby weights again. In the interest of saving space, we’re only looking at the first two babies from the previous table of data.
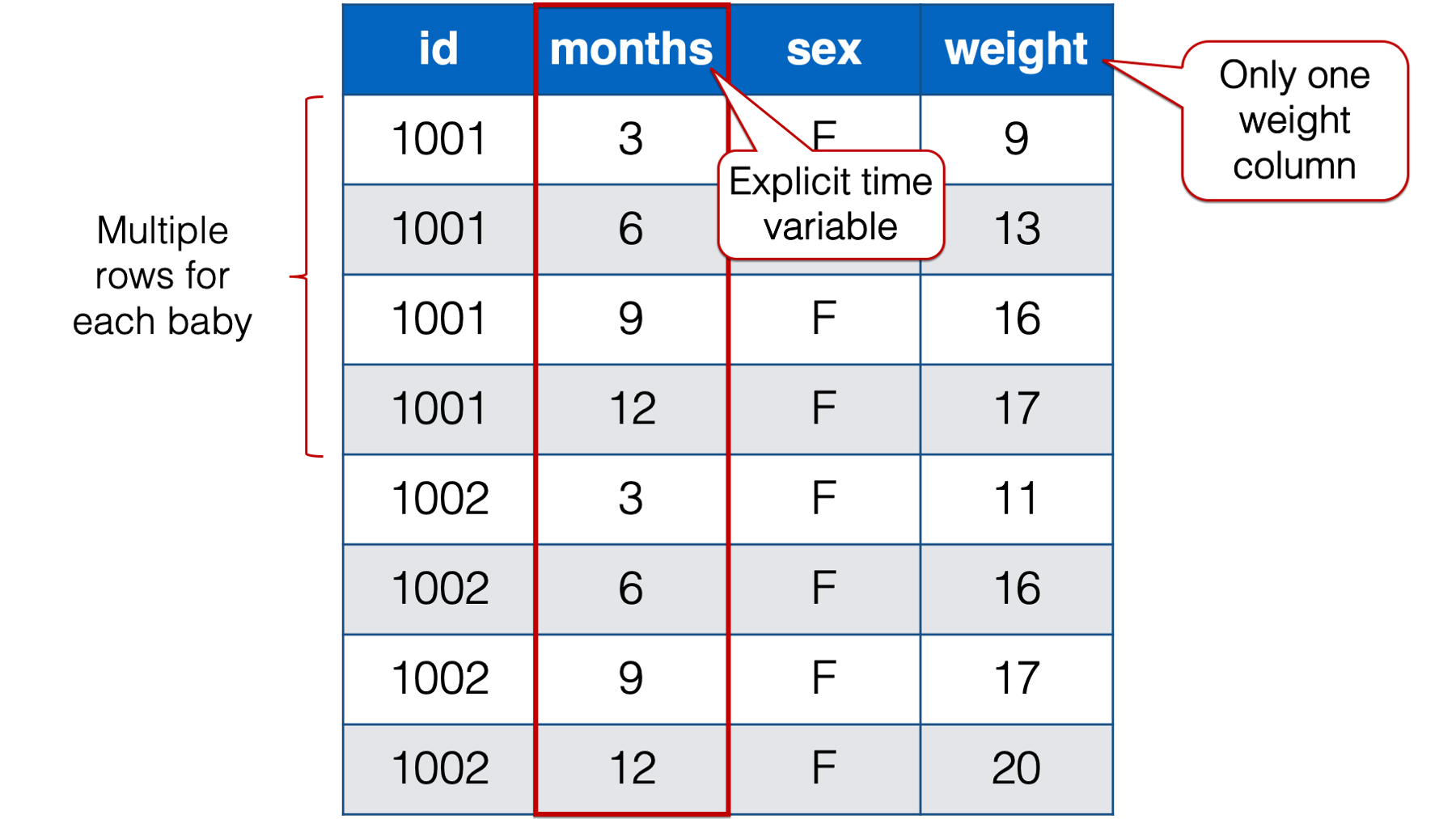
Figure 32.5: Baby weights at 3, 6, 9 , and 12 months. Babies 1001 and 1002 only.
Notice that each baby in the person-period table has four rows – one for each weight measurement. Also notice that there is a new variable in the person-period data that explicitly records time (i.e., months).
🗒Side Note: Let’s quickly learn a couple of new terms: time-varying and time-invariant variables. In the data above, sex is time invariant. It remains constant over all 4 measurement occasions for each baby. Not only that, but for all intents and purposes it isn’t really allowed to change. The weight variable, on the other hand, is time varying. The weight values change over time. And not only do they change, but the amount, rate, and/or shape of their change may be precisely what this researcher is interested in.
Below, we can compare the person-level version of the baby weight data to the person-period version of the baby weight data. I’m only including babies 1001 and 1002 in the interest of saving space. As you can see, given the same data, the person-level structure is wider (i.e., more columns) than the person-period data and the person-period structure is longer (i.e., more rows) than the person-level data. That’s why the two structures are sometimes referred to as wide and long respectively.
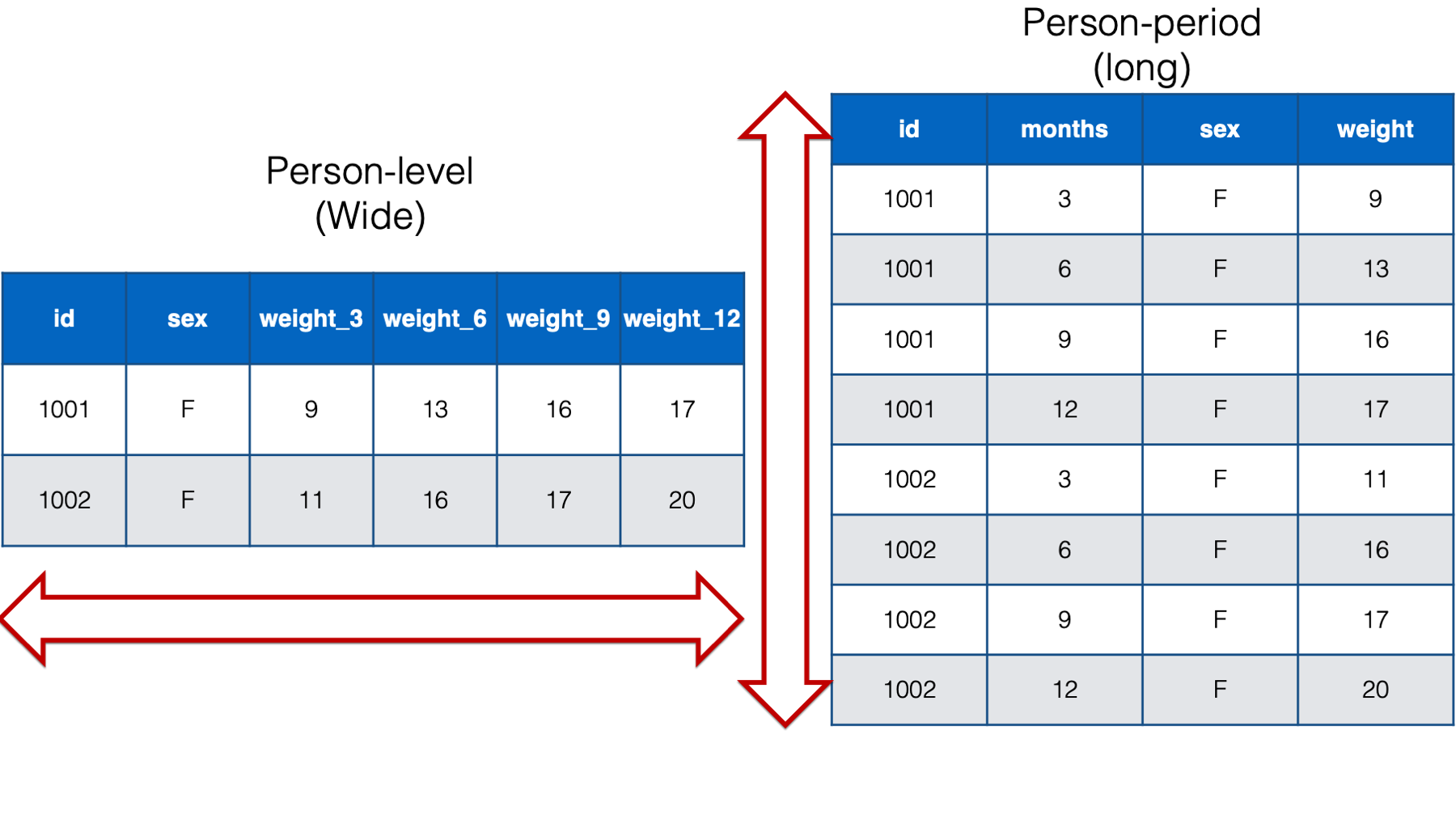
Figure 32.6: Comparing wide and long data for the babies 1001 and 1002.
Ok, so this data can be structured in either a person-level or a person-period format, but which structure should we use?
Well, in general, I’m going to suggest that you use the person-period structure for the kind of longitudinal data we have above for the following reasons:
It contains an explicit time variable. The time information may be descriptively interesting on its own, or we may need to include it in our statistical models. In fact, many longitudinal analyses will require that our data have a person-period structure. For example, mixed models, gereralized estimating equations, and survival analysis.
The person-period structure can be more efficient when we the intervals between repeated measures vary across observational units. For example, in the data above the baby weight columns were named
weight_3,weight_6,weight_9, andweight_12, which indicated each baby’s weight at a 3-month, 6-month, 9-month, and 12-month checkup. However, what if the study needed a more precise measure of each baby’s age. Let’s say that we needed to record each baby’s weight at their precise age in days at each checkup. That might look something like the following if structured in a person-level format:
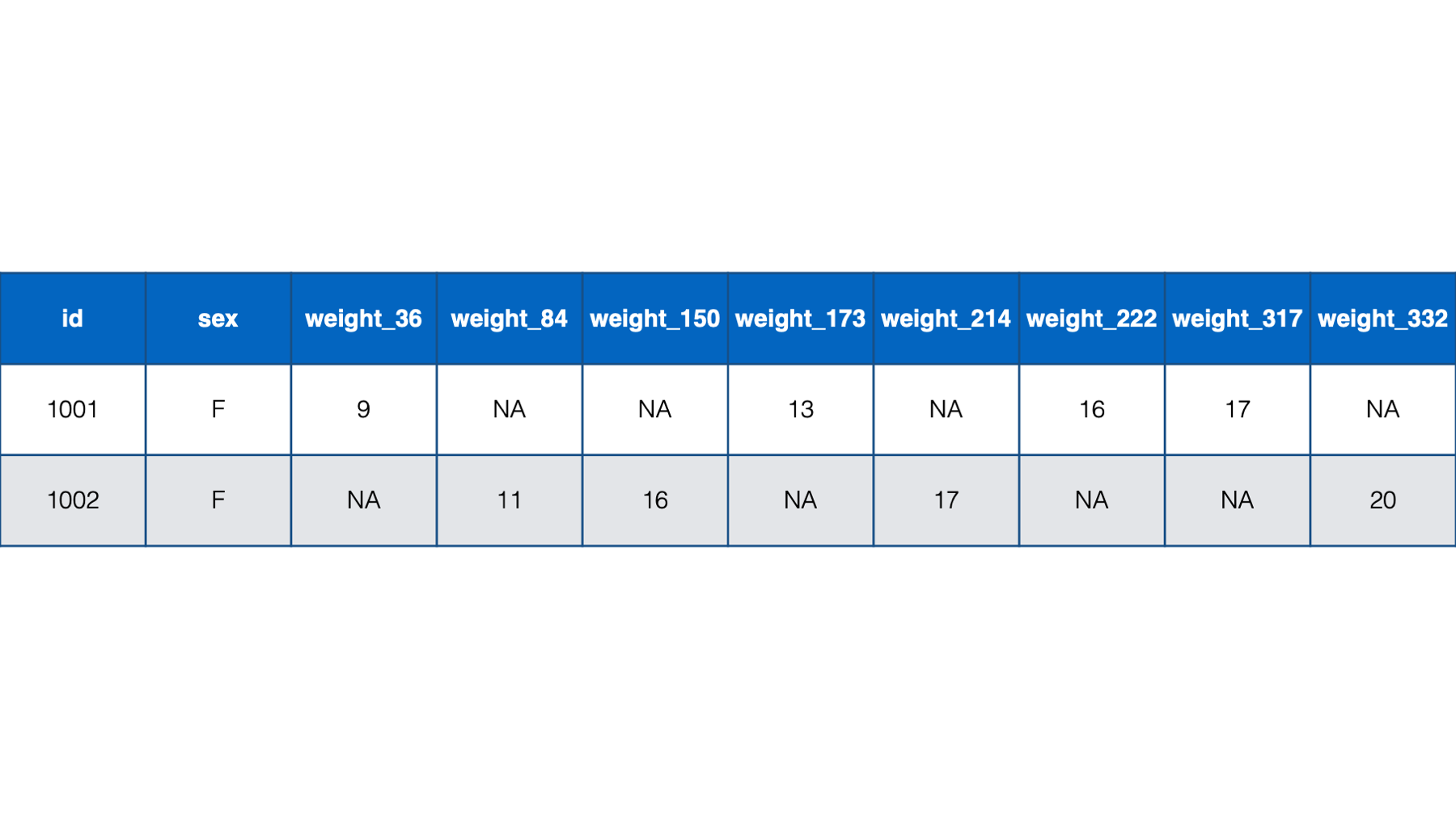
Figure 32.7: Baby weights at age in days. Babies 1001 and 1002 only.
Notice all the missing data in this format – even with only two babies. For example, baby 1001 had her first check-up at 36 days old. She was 9 lbs. Baby 1002, however, didn’t have her first checkup until she was 84 days old. So, baby 1002 has a missing value for weight_36. That pattern continues throughout the data. Now, just try to imagine what this would look like for tens, hundreds, or thousands of babies. It would be a mess! By contrast, the person-period version of this data is much more efficient. In fact, it looks almost identical to the first person-period version of this data:
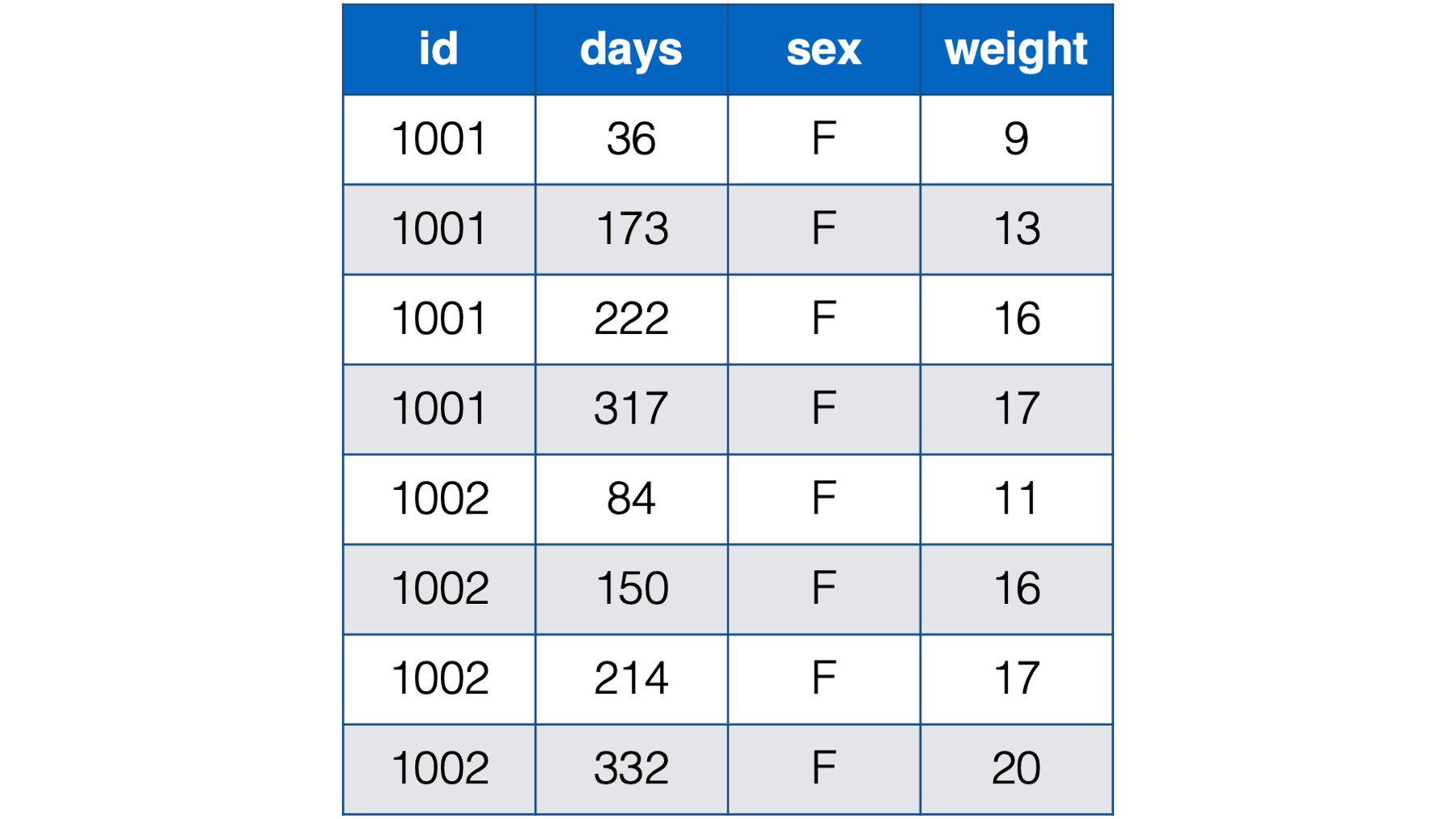
Figure 32.8: Baby weights at age in days. Babies 1001 and 1002 only.
For essentially the same reasons already discussed above, the person-period format is better suited for handling time-varying predictors. In the baby weight data, the only predictor variable (other than time) was sex, which is time invariant. Regardless of which structure we use, sex only requires one column in the data frame because it never changes. However, imagine a scenario where we also collect height and information about diet at each visit. Using a person-level structure to store these variables would have the same limitations that we already discussed above (i.e., no explicit measure of time, incompatibility with many analysis techniques, and potentially inefficient storage).
Many of the “tidyverse” packages we use in this book (e.g.,
dplyrandggplot2) assume, or at least work best, with data organized in a person-period, or long, format.
So, does this mean that we should never organize our data frames in a person-level format? Of course not! There are going to be some occasions when there are advantages to organizing our data frames in a person-level format. For example:
Many people prefer the person-level format during the data entry process because it can require less typing. Thinking about our baby weight data above, we would only need to type one new value at each checkup (i.e., weight) if the data is organized in a person-level format. However, if the data is organized in a person-period format, we have to type three new values (i.e., id, sex, and weight). This limitation grows with the number of time-invariant variables in the data.
There are some analyses that will require that our data have a person-level structure. For example, the traditional ANOVA and MANOVA techniques assume the wide format.
There are times when our data is easier to manipulate when it is organized in a person-level format.
There are times when it’s advantageous to restructure statistical results from a longer format to a wider format to present them in the most effective way possible.
Luckily, we rarely have to choose one structure or the other in an absolute sense. The tidyr package generally makes it very easy for us to restructure (“reshape” is another commonly used term) our data frames from wide to long and back again. This allows us to organize our data in the manner that is best suited for the particular task at hand. Let’s go ahead and take a look at some examples.
32.1 The tidyr package
The tools we will use for restructuring our data will primarily come from a package we haven’t used before in this book – tidyr. If you haven’t already done so, and you’d like to follow along, please install and load tidyr, dplyr, and ggplot2 now.
32.2 Pivoting longer
In epidemiology, it’s common for data that we analyze to be measured on multiple occasions. It’s also common for repeated measures data to be entered into a spreadsheet or database in such a way that each new measure is a new column. We saw an example of this above:
Figure 32.9: Baby weights at 3, 6, 9 , and 12 months
We already concluded that this data has a person-level (wide) structure. As discussed above, many techniques that we may want to use to analyze this data will require us to restructure it to a person-period format. Let’s go ahead and walk through a demonstration of how do that. We will start by simulating this data in R:
babies <- tibble(
id = 1001:1008,
sex = c("F", "F", "M", "F", "M", "M", "M", "F"),
weight_3 = c(9, 11, 17, 16, 11, 17, 16, 15),
weight_6 = c(13, 16, 20, 18, 15, 21, 17, 16),
weight_9 = c(16, 17, 23, 21, 16, 25, 19, 18),
weight_12 = c(17, 20, 24, 22, 18, 26, 21, 19)
) %>%
print()## # A tibble: 8 × 6
## id sex weight_3 weight_6 weight_9 weight_12
## <int> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1001 F 9 13 16 17
## 2 1002 F 11 16 17 20
## 3 1003 M 17 20 23 24
## 4 1004 F 16 18 21 22
## 5 1005 M 11 15 16 18
## 6 1006 M 17 21 25 26
## 7 1007 M 16 17 19 21
## 8 1008 F 15 16 18 19Now, let’s use the pivot_longer() function to restructure the babies data frame to a person-period format:
babies_long <- babies %>%
pivot_longer(
cols = starts_with("weight"),
names_to = "months",
names_prefix = "weight_",
values_to = "weight"
) %>%
print()## # A tibble: 32 × 4
## id sex months weight
## <int> <chr> <chr> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1002 F 3 11
## 6 1002 F 6 16
## 7 1002 F 9 17
## 8 1002 F 12 20
## 9 1003 M 3 17
## 10 1003 M 6 20
## # ℹ 22 more rows👆Here’s what we did above:
We used
tidyr’spivot_longer()function to restructure thebabiesdata frame from person-level (wide) to person-period (long).You can type
?pivot_longerinto your R console to view the help documentation for this function and follow along with the explanation below.The first argument to the
pivot_longer()function is thedataargument. You should pass the name of the data frame you want to restructure to thedataargument. Above, we passed thebabiesdata frame to thedataargument using a pipe operator.The second argument to the
pivot_longer()function is thecolsargument. You should pass the name of the columns you want to make longer to thecolsargument. Above, we passed the names of the four weight columns to thecolsargument. Thecolsargument actually accepts tidy-select argument modifiers. We first discussed tidy-select argument modifiers in the chapter on subsetting data frames. In the example above, we used thestarts_with()tidy-select modifier to simplify our code. Instead of passing each column name directly to thecolsargument, we askedstarts_with()to pass the name of any column that has a column name that starts with the word “weight” to thecolsargument.The third argument to the
pivot_longer()function is thenames_toargument. You should pass thenames_toargument a character string or character vector that tellspivot_longer()what you want to name the column that will contain the previous column names that were pivoted. By default, the value passed to thenames_toargument is"name". We passed the value"months"to thenames_toargument. This tellspivot_longer()what to name the column that contains the names of the previous column names. If that seems really confusing, I’m with you. Unfortunately, I don’t currently know a better way to write it, but I will show you what thenames_toargument does below.The fourth argument to the
pivot_longer()function is thenames_prefixargument. You should pass thenames_prefixargument a regular expression that tellspivot_longer()what to remove from the start of each of the previous column names that we pivoted. By default, the value passed to thenames_prefixargument isNULL(i.e., it doesn’t remove anything). We passed the value"weight_"to thenames_prefixargument. This tellspivot_longer()that we want to remove the character string “weight_” from the start of each of the previous column names that we pivoted. For example, removing “weight_” from “weight_3” results in the value “3”, removing “weight_” from “weight_6” results in the value “6”, and so on. Again, I will show you what thenames_prefixargument does below.The eighth argument (we left the 5th, 6th, and 7th arguments at their default values) to the
pivot_longer()function is thevalues_toargument. You should pass thevalues_toargument a character string or character vector that tellspivot_longer()what you want to name the column that will contain the values from the columns that were pivoted. By default, the value passed to thevalues_toargument is"value". We passed the value"weight"to thevalues_toargument. This tellspivot_longer()what to name the column that contains values from the columns that were pivoted. I will demonstrate what thevalues_toargument does below as well.
32.2.1 The names_to argument
The official help documentation for pivot_longer() says that the value passed to the names_to argument should be “a string specifying the name of the column to create from the data stored in the column names of data.” I don’t blame you if you feel like that’s a little bit difficult to wrap your head around. Let’s take a look at the result we get when we don’t adjust the value passed to the names_to argument:
## # A tibble: 32 × 4
## id sex name value
## <int> <chr> <chr> <dbl>
## 1 1001 F weight_3 9
## 2 1001 F weight_6 13
## 3 1001 F weight_9 16
## 4 1001 F weight_12 17
## 5 1002 F weight_3 11
## 6 1002 F weight_6 16
## 7 1002 F weight_9 17
## 8 1002 F weight_12 20
## 9 1003 M weight_3 17
## 10 1003 M weight_6 20
## # ℹ 22 more rows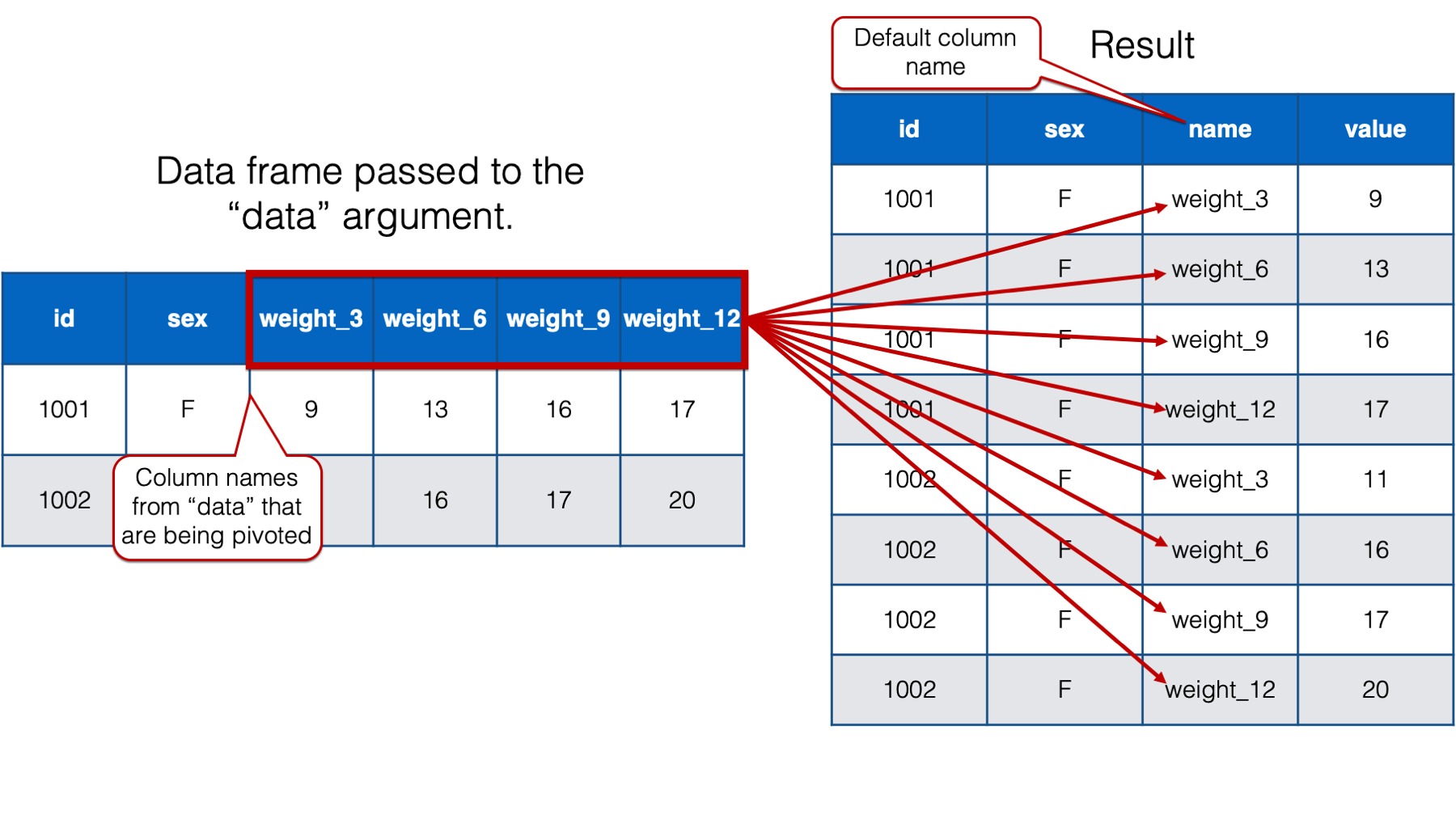
As you can see, when we only pass a value to the cols argument, pivot_longer() creates a new column that contains the column names from the data frame passed to the data argument, that are being pivoted into long format. By default, pivot_longer() names that column name. However, that name isn’t very informative. We will go ahead and change the column name to “months” because we know that this column will eventually contain month values. We do so by passing the value "months" to the names_to argument like this:
## # A tibble: 32 × 4
## id sex months value
## <int> <chr> <chr> <dbl>
## 1 1001 F weight_3 9
## 2 1001 F weight_6 13
## 3 1001 F weight_9 16
## 4 1001 F weight_12 17
## 5 1002 F weight_3 11
## 6 1002 F weight_6 16
## 7 1002 F weight_9 17
## 8 1002 F weight_12 20
## 9 1003 M weight_3 17
## 10 1003 M weight_6 20
## # ℹ 22 more rows32.2.2 The names_prefix argument
The official help documentation for pivot_longer() says that the value passed to the names_prefix argument should be “a regular expression used to remove matching text from the start of each variable name.” Passing a value to this argument can be really useful when column names actually contain data values, which was the case above. Take the column name “weight_3” for example. The “weight” part is truly a column name – it tells us what the values in that column are. They are weights. The “3” part is actually a separate data value meaning “3 months.” If we can remove the “weight_” part of the column name, then what remains is a useful column of information – time measured in months. Passing the value “weight_” to the names_prefix argument does exactly that.
babies %>%
pivot_longer(
cols = starts_with("weight"),
names_to = "months",
names_prefix = "weight_"
)## # A tibble: 32 × 4
## id sex months value
## <int> <chr> <chr> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1002 F 3 11
## 6 1002 F 6 16
## 7 1002 F 9 17
## 8 1002 F 12 20
## 9 1003 M 3 17
## 10 1003 M 6 20
## # ℹ 22 more rowsNow, the value passed to the names_prefix argument can be any regular expression. So, we could have written a more complicated, and flexible, regular expression like this:
babies %>%
pivot_longer(
cols = starts_with("weight"),
names_to = "months",
names_prefix = "\\w+_"
)## # A tibble: 32 × 4
## id sex months value
## <int> <chr> <chr> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1002 F 3 11
## 6 1002 F 6 16
## 7 1002 F 9 17
## 8 1002 F 12 20
## 9 1003 M 3 17
## 10 1003 M 6 20
## # ℹ 22 more rowsThe regular expression above would have removed any word characters followed by an underscore. However, in this case, the value "weight_" is straightforward and gets the job done.
32.2.3 The values_to argument
The official help documentation for pivot_longer() says that the value passed to the values_to argument should be “a string specifying the name of the column to create from the data stored in cell values.” All that means is that we use this argument to name the column that contains the values that were pivoted.
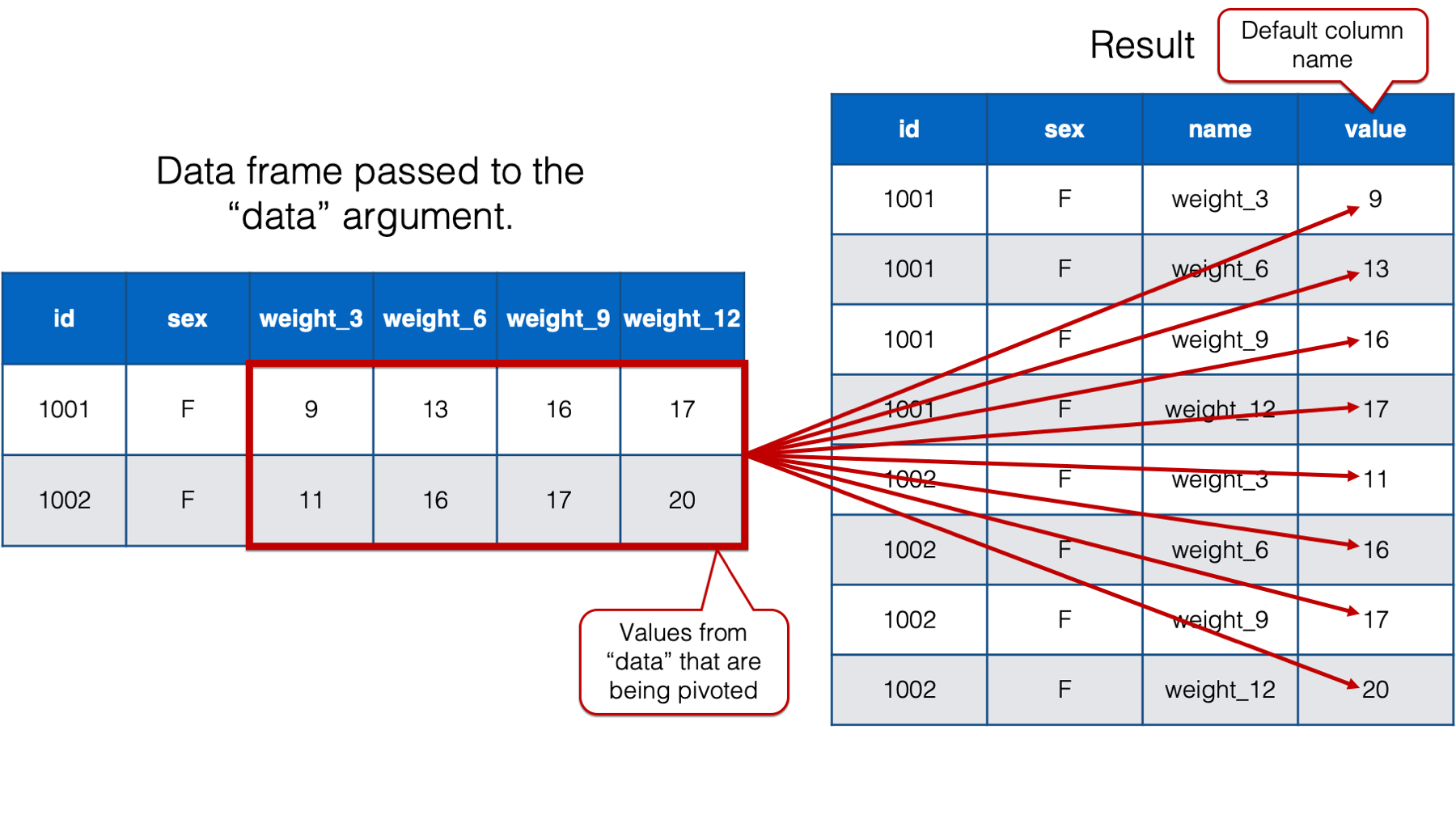
By default, pivot_longer() names that column “value.” However, we will once again want a more informative column name in our new data frame. So, we’ll go ahead and change the column name to “weight” because that’s what the values in that column are – weights. We do so by passing the value "weight" to the values_to argument like this:
babies %>%
pivot_longer(
cols = starts_with("weight"),
names_to = "months",
names_prefix = "weight_",
values_to = "weight"
)## # A tibble: 32 × 4
## id sex months weight
## <int> <chr> <chr> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1002 F 3 11
## 6 1002 F 6 16
## 7 1002 F 9 17
## 8 1002 F 12 20
## 9 1003 M 3 17
## 10 1003 M 6 20
## # ℹ 22 more rows32.2.4 The names_transform argument
As one little final touch on the data restructuring at hand, it would be nice to coerce the months column from type character to type integer. We already know how to do this with mutate():
babies %>%
pivot_longer(
cols = starts_with("weight"),
names_to = "months",
names_prefix = "weight_",
values_to = "weight"
) %>%
mutate(months = as.integer(months))## # A tibble: 32 × 4
## id sex months weight
## <int> <chr> <int> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1002 F 3 11
## 6 1002 F 6 16
## 7 1002 F 9 17
## 8 1002 F 12 20
## 9 1003 M 3 17
## 10 1003 M 6 20
## # ℹ 22 more rowsHowever, we can also do this directly inside the pivot_longer() function by passing a list of column names paired with type coercion functions. For example:
babies %>%
pivot_longer(
cols = starts_with("weight"),
names_to = "months",
names_prefix = "weight_",
names_transform = list(months = as.integer),
values_to = "weight"
)## # A tibble: 32 × 4
## id sex months weight
## <int> <chr> <int> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1002 F 3 11
## 6 1002 F 6 16
## 7 1002 F 9 17
## 8 1002 F 12 20
## 9 1003 M 3 17
## 10 1003 M 6 20
## # ℹ 22 more rows👆Here’s what we did above:
- We coerced the
monthscolumn from type character to type integer by passing the valuelist(months = as.integer)to thenames_transformargument. The list passed tonames_transformshould contain one or more column names paired with a type coercion function. The column name and type coercion function should be paired using an equal sign. Multiple pairs should be separated by commas.
32.2.5 Pivoting multiple sets of columns
Let’s add a little layer of complexity to our situation. Let’s say that our babies data frame also includes each baby’s length in inches measured at each visit:
set.seed(123)
babies <- tibble(
id = 1001:1008,
sex = c("F", "F", "M", "F", "M", "M", "M", "F"),
weight_3 = c(9, 11, 17, 16, 11, 17, 16, 15),
weight_6 = c(13, 16, 20, 18, 15, 21, 17, 16),
weight_9 = c(16, 17, 23, 21, 16, 25, 19, 18),
weight_12 = c(17, 20, 24, 22, 18, 26, 21, 19),
length_3 = c(17, 19, 23, 20, 18, 22, 21, 18),
length_6 = round(length_3 + rnorm(8, 2, 1)),
length_9 = round(length_6 + rnorm(8, 2, 1)),
length_12 = round(length_9 + rnorm(8, 2, 1)),
) %>%
print()## # A tibble: 8 × 10
## id sex weight_3 weight_6 weight_9 weight_12 length_3 length_6 length_9 length_12
## <int> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1001 F 9 13 16 17 17 18 19 21
## 2 1002 F 11 16 17 20 19 21 23 23
## 3 1003 M 17 20 23 24 23 27 30 33
## 4 1004 F 16 18 21 22 20 22 24 26
## 5 1005 M 11 15 16 18 18 20 22 23
## 6 1006 M 17 21 25 26 22 26 28 30
## 7 1007 M 16 17 19 21 21 23 24 25
## 8 1008 F 15 16 18 19 18 19 23 24Here is what we want our final data frame to look like:
## # A tibble: 32 × 5
## id sex months weight length
## <int> <chr> <chr> <dbl> <dbl>
## 1 1001 F 3 9 17
## 2 1001 F 6 13 18
## 3 1001 F 9 16 19
## 4 1001 F 12 17 21
## 5 1002 F 3 11 19
## 6 1002 F 6 16 21
## 7 1002 F 9 17 23
## 8 1002 F 12 20 23
## 9 1003 M 3 17 23
## 10 1003 M 6 20 27
## # ℹ 22 more rowsNext, we’ll walk through getting to this result step-by-step.
We are once again starting with a person-level data frame, and we once again want to restructure it to a person-period data frame. This is the result we get if we use the same code we previously used to restructure the data frame that didn’t include each baby’s length:
babies_long <- babies %>%
pivot_longer(
cols = starts_with("weight"),
names_to = "months",
names_prefix = "weight_",
values_to = "weight"
) %>%
print()## # A tibble: 32 × 8
## id sex length_3 length_6 length_9 length_12 months weight
## <int> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <dbl>
## 1 1001 F 17 18 19 21 3 9
## 2 1001 F 17 18 19 21 6 13
## 3 1001 F 17 18 19 21 9 16
## 4 1001 F 17 18 19 21 12 17
## 5 1002 F 19 21 23 23 3 11
## 6 1002 F 19 21 23 23 6 16
## 7 1002 F 19 21 23 23 9 17
## 8 1002 F 19 21 23 23 12 20
## 9 1003 M 23 27 30 33 3 17
## 10 1003 M 23 27 30 33 6 20
## # ℹ 22 more rowsBecause we aren’t passing any of the length_ columns to the cols argument, pivot_longer() is treating them like the other time-invariant variables (i.e., id and sex). Their values are just being recycled across every row within each id. So, let’s add the length_ columns to the cols argument and see what happens:
babies_long <- babies %>%
pivot_longer(
cols = c(-id, -sex),
names_to = "months",
names_prefix = "weight_",
values_to = "weight"
) %>%
print()## # A tibble: 64 × 4
## id sex months weight
## <int> <chr> <chr> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1001 F length_3 17
## 6 1001 F length_6 18
## 7 1001 F length_9 19
## 8 1001 F length_12 21
## 9 1002 F 3 11
## 10 1002 F 6 16
## # ℹ 54 more rows👆Here’s what we did above:
- We passed the
weight_andlength_columns to thecolsargument indirectly by passing the valuec(-id, -sex). Basically, this tellspivot_longer()that we would like to pivot every column exceptidandsex.
Now, we are pivoting both the weight_ columns and the length_ columns. That’s an improvement. However, we obviously still don’t have the result we want.
Remember that the value passed to the names_prefix argument is used to remove matching text from the start of each variable name. Passing the value "weight_" to the names_prefix argument made sense when all of our pivoted columns began with the character sting “weight_”. Now, however, some of our pivoted columns begin with the character string “length_”. That’s why we are still seeing values in the months column like length_3, length_6, and so on.
Now, your first instinct might be to just add "length_" to the names_prefix argument. Unfortunately, that doesn’t work:
babies_long <- babies %>%
pivot_longer(
cols = c(-id, -sex),
names_to = "months",
names_prefix = c("weight_", "length_"),
values_to = "weight"
) %>%
print()## Warning in gsub(vec_paste0("^", names_prefix), "", cols): argument 'pattern' has length > 1 and only the first element will be used## # A tibble: 64 × 4
## id sex months weight
## <int> <chr> <chr> <dbl>
## 1 1001 F 3 9
## 2 1001 F 6 13
## 3 1001 F 9 16
## 4 1001 F 12 17
## 5 1001 F length_3 17
## 6 1001 F length_6 18
## 7 1001 F length_9 19
## 8 1001 F length_12 21
## 9 1002 F 3 11
## 10 1002 F 6 16
## # ℹ 54 more rowsInstead, we need to drop the names_prefix argument altogether before we can move forward to the correct solution:
babies_long <- babies %>%
pivot_longer(
cols = c(-id, -sex),
names_to = "months",
values_to = "weight"
) %>%
print()## # A tibble: 64 × 4
## id sex months weight
## <int> <chr> <chr> <dbl>
## 1 1001 F weight_3 9
## 2 1001 F weight_6 13
## 3 1001 F weight_9 16
## 4 1001 F weight_12 17
## 5 1001 F length_3 17
## 6 1001 F length_6 18
## 7 1001 F length_9 19
## 8 1001 F length_12 21
## 9 1002 F weight_3 11
## 10 1002 F weight_6 16
## # ℹ 54 more rowsAdditionally, not all the values in the third column (i.e., weight) are weights. Half of those values are lengths. So, we also need to drop the values_to argument:
## # A tibble: 64 × 4
## id sex months value
## <int> <chr> <chr> <dbl>
## 1 1001 F weight_3 9
## 2 1001 F weight_6 13
## 3 1001 F weight_9 16
## 4 1001 F weight_12 17
## 5 1001 F length_3 17
## 6 1001 F length_6 18
## 7 1001 F length_9 19
## 8 1001 F length_12 21
## 9 1002 F weight_3 11
## 10 1002 F weight_6 16
## # ℹ 54 more rowsBelieve it or not, we are actually pretty close to accomplishing our goal. Next, we need to somehow tell pivot_longer() that the column names we are pivoting contain a description of the values (i.e., heights and weights) and time values (i.e., 3, 6, 9, and 12 months). Notice that in all cases, the description and the time value are separated by an underscore. It turns out that we can use the names_sep argument to give pivot_longer() this information.
32.2.6 The names_sep argument
Let’s start by simply passing the adding the names_sep argument to the pivot_longer() function and pass it the value that separates our description and our time value:
babies_long <- babies %>%
pivot_longer(
cols = c(-id, -sex),
names_to = "months",
names_sep = "_"
) %>%
print()## Error in `pivot_longer()`:
## ! `names_sep` can't be used with a length 1 `names_to`.And we get an error. The reason we get an error can be seen in the following figure:
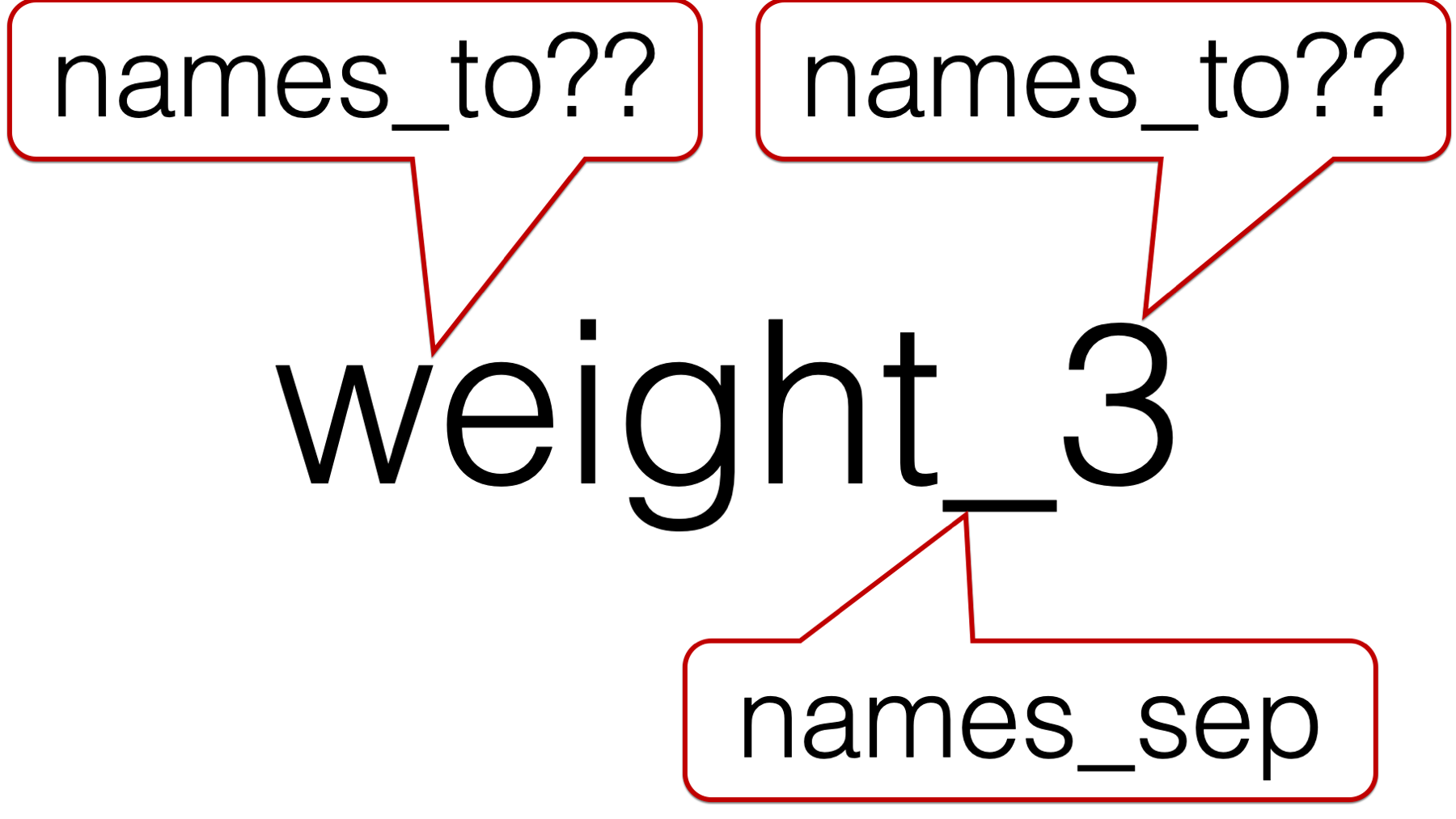
We are asking pivot_longer() to break up each column name (e.g., weight_3) at the underscore. That results in creating two separate character strings. In this case, the character string “weight” and the character string “3”. However, we only passed one value to the names_to argument – "months". So, which character string should pivot_longer() put in the months column? Of course, we know that the answer is “3”, but pivot_longer() doesn’t know that.
So, we have to pass two values to the names_to argument. But, what values should we pass?
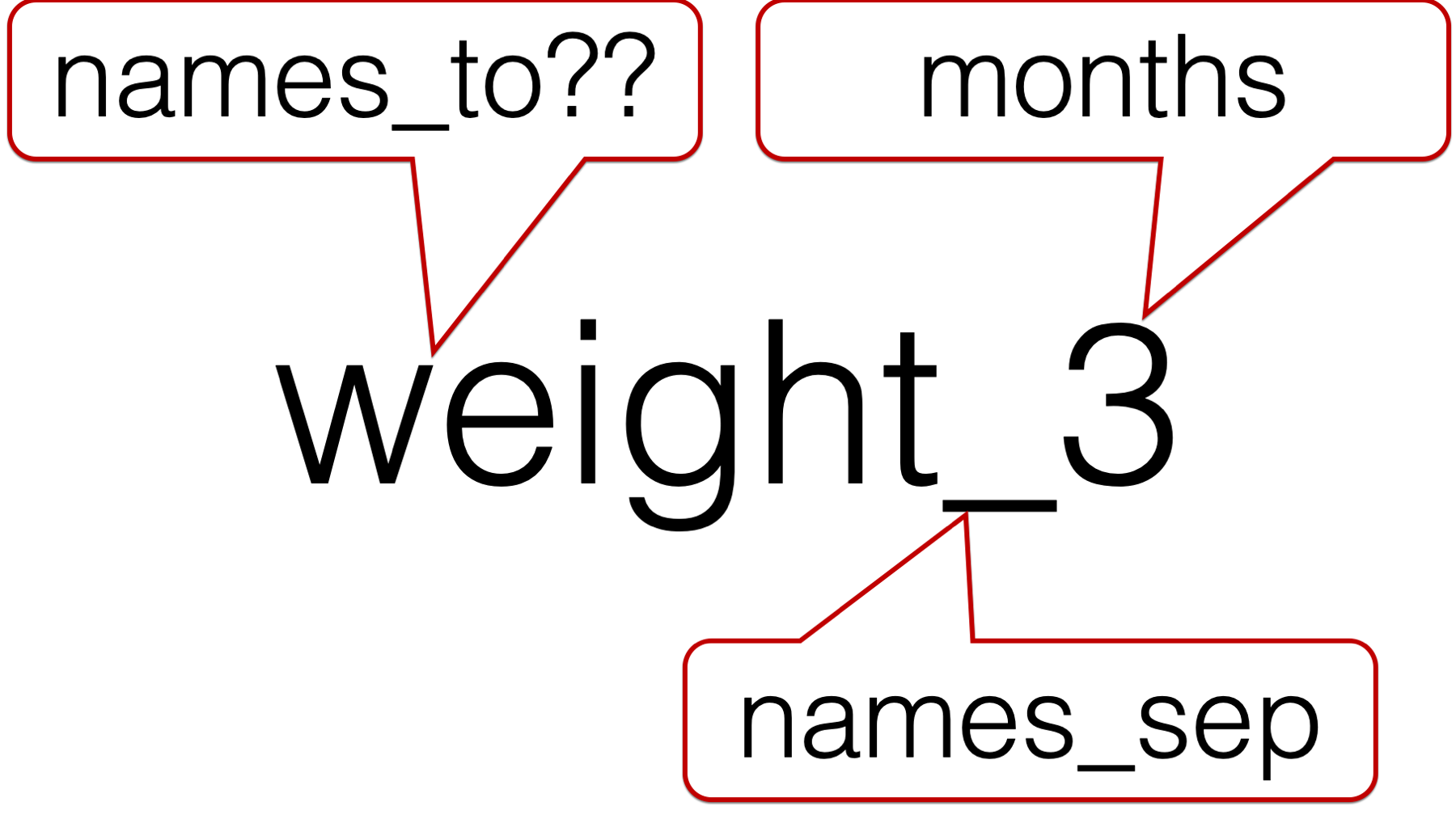
We obviously want to character string that comes after the underscore to be called “months”. However, we can’t call the character string in front of the underscore “weight” because this column isn’t just identifying rows that contain weights. Similarly, we can’t call the character string in front of the underscore “length” because this column isn’t just identifying rows that contain lengths. For lack of a better idea, let’s just call it “measure”.
babies_long <- babies %>%
pivot_longer(
cols = c(-id, -sex),
names_to = c("measure", "months"),
names_sep = "_"
) %>%
print()## # A tibble: 64 × 5
## id sex measure months value
## <int> <chr> <chr> <chr> <dbl>
## 1 1001 F weight 3 9
## 2 1001 F weight 6 13
## 3 1001 F weight 9 16
## 4 1001 F weight 12 17
## 5 1001 F length 3 17
## 6 1001 F length 6 18
## 7 1001 F length 9 19
## 8 1001 F length 12 21
## 9 1002 F weight 3 11
## 10 1002 F weight 6 16
## # ℹ 54 more rowsThat sort of works. Except, what we really want is one row for each combination of id and months, each containing a value for weight and length. Instead, we have two rows for each combination of id and months. One set of rows contains weights and the other set of rows contains lengths.
What we really need is for pivot_longer() to make weight one column and length a separate column, and then put the appropriate values from value under each. We can do this with the .value special value.
32.2.7 The .value special value
The official help documentation for pivot_longer() says that the .value special value “indicates that [the] component of the name defines the name of the column containing the cell values, overriding values_to.” Said another way, .value tells pivot_longer() the character string in front of the underscore is the value description. Further, .value tells pivot_longer() to create a new column for each unique character string that is in front of the underscore.
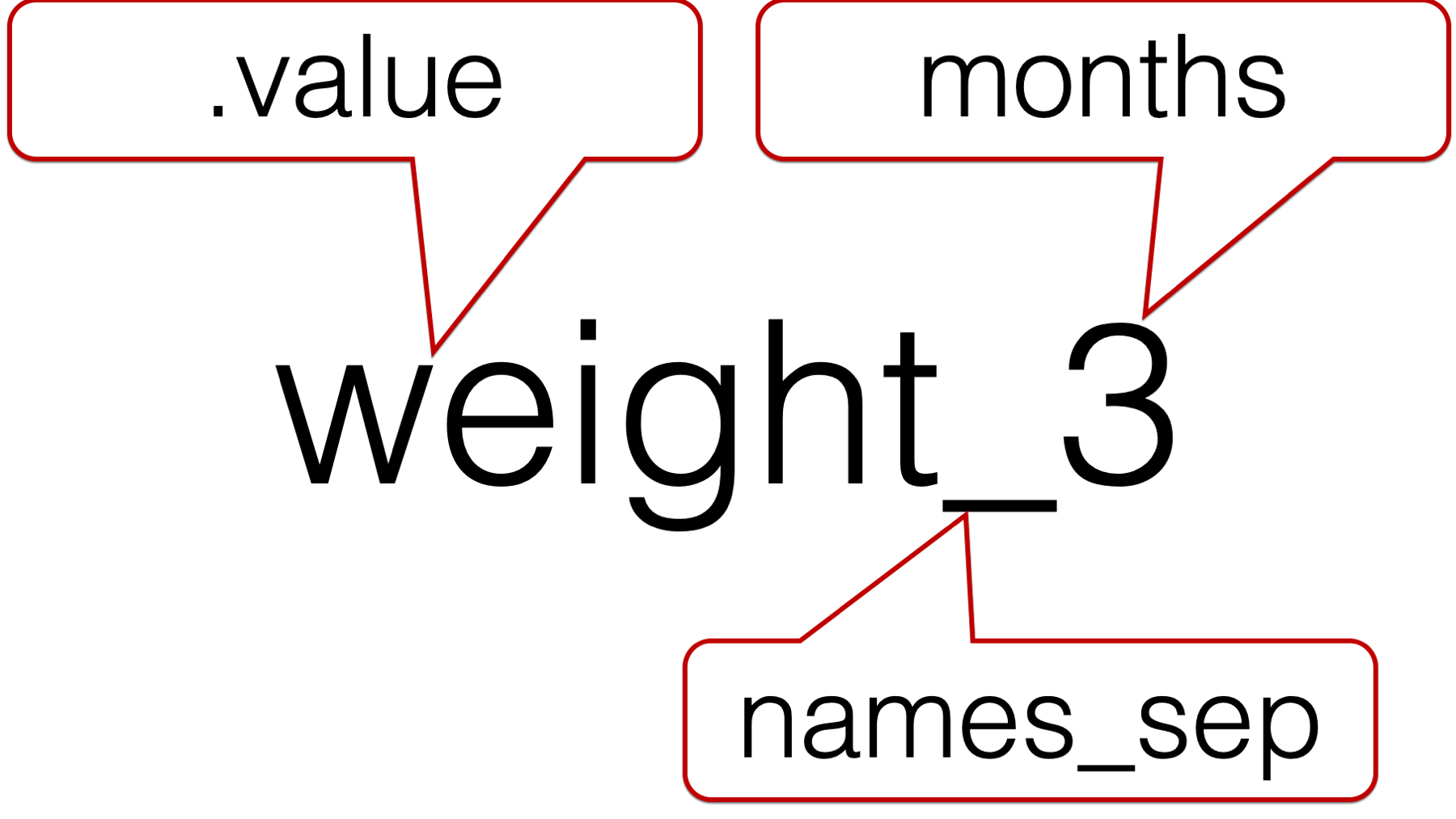
Now, let’s add the .value special value to our code:
babies_long <- babies %>%
pivot_longer(
cols = c(-id, -sex),
names_to = c(".value", "months"),
names_sep = "_",
names_transform = list(months = as.integer)
) %>%
print()## # A tibble: 32 × 5
## id sex months weight length
## <int> <chr> <int> <dbl> <dbl>
## 1 1001 F 3 9 17
## 2 1001 F 6 13 18
## 3 1001 F 9 16 19
## 4 1001 F 12 17 21
## 5 1002 F 3 11 19
## 6 1002 F 6 16 21
## 7 1002 F 9 17 23
## 8 1002 F 12 20 23
## 9 1003 M 3 17 23
## 10 1003 M 6 20 27
## # ℹ 22 more rowsAnd that is exactly the result we wanted. However, there was one little detail we didn’t cover. How does .value know to create a new column for each unique character string that is in front of the underscore. Why didn’t it create a new column for each unique character string that is behind the underscore?
The answer is simple. It knows because of the ordering we used in the value we passed to the names_to argument. If we changed the order to c("months", ".value"), pivot_longer() would have created a new column for each unique character string that is behind the underscore. Take a look:
## # A tibble: 16 × 7
## id sex months `3` `6` `9` `12`
## <int> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1001 F weight 9 13 16 17
## 2 1001 F length 17 18 19 21
## 3 1002 F weight 11 16 17 20
## 4 1002 F length 19 21 23 23
## 5 1003 M weight 17 20 23 24
## 6 1003 M length 23 27 30 33
## 7 1004 F weight 16 18 21 22
## 8 1004 F length 20 22 24 26
## 9 1005 M weight 11 15 16 18
## 10 1005 M length 18 20 22 23
## 11 1006 M weight 17 21 25 26
## 12 1006 M length 22 26 28 30
## 13 1007 M weight 16 17 19 21
## 14 1007 M length 21 23 24 25
## 15 1008 F weight 15 16 18 19
## 16 1008 F length 18 19 23 24So, be careful about the ordering of the values you pass to the names_to argument.
32.2.8 Why person-period?
Why might we want the babies data in this person-period format? Well, as we discussed above, there are many analytic techniques that require our data to be in this format. Unfortunately, those techniques are beyond the scope of this chapter. However, this person-period format is still necessary for something as simple as plotting baby weight against baby height as we’ve done in the scatter plot below:
babies_long %>%
mutate(months = factor(months, c(3, 6, 9, 12))) %>%
ggplot() +
geom_point(aes(weight, length, color = months)) +
labs(
x = "Weight (Pounds)",
y = "Length (Inches)",
color = "Age (Months)"
) +
theme_classic()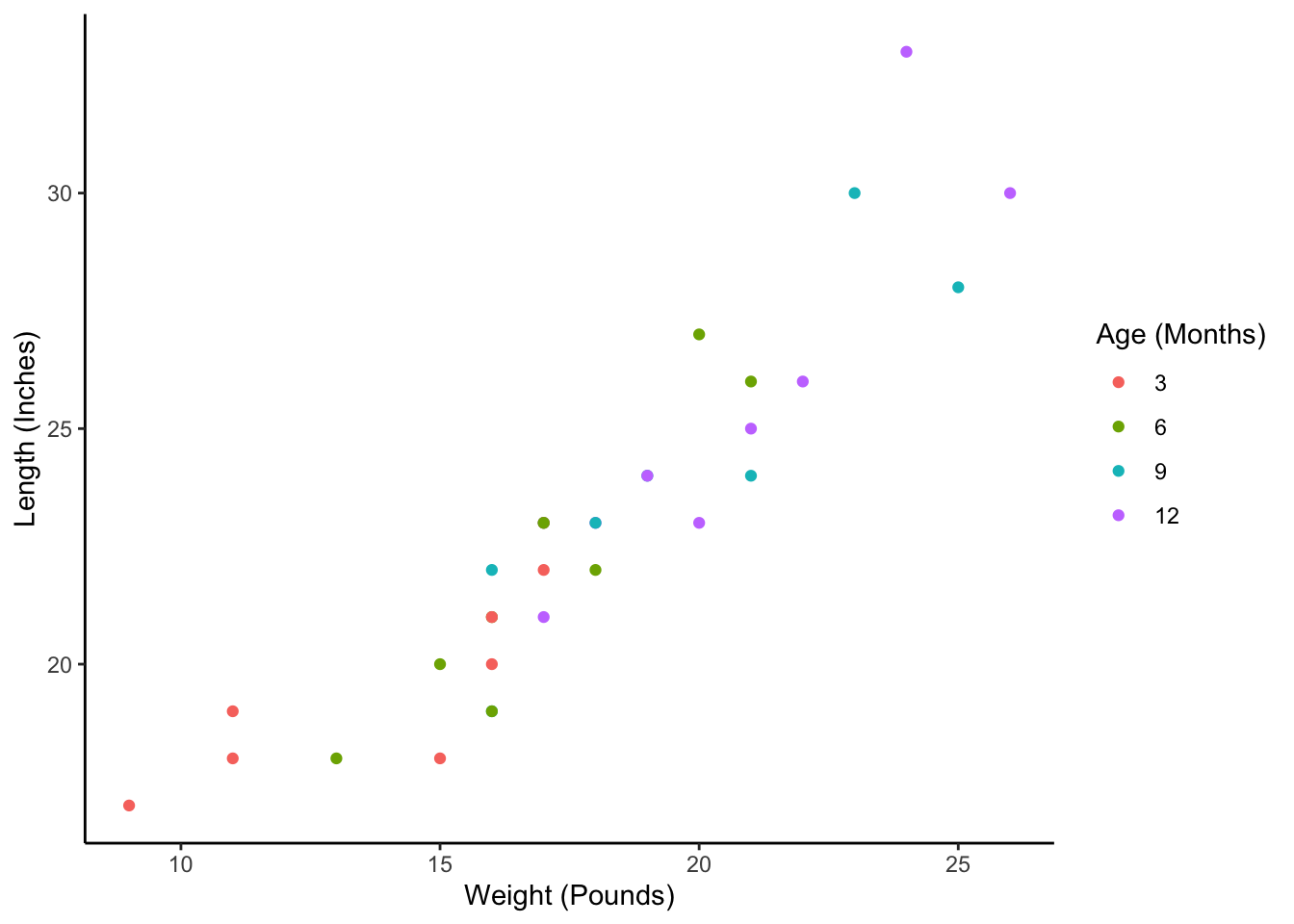
32.3 Pivoting wider
As previously discussed, the person-period, or long, data structure is usually preferable for longitudinal data analysis. However, there are times when the person-level data structure is preferable, or even necessary. Further, there are times when we have tables of analysis results, as opposed than actual data values, that we need to restructure for ease of interpretation. We will demonstrate how to do both below.
We’ll start by learning how to restructure, or reshape, our person-period babies_long data frame back to a person-level format. As a reminder, here is what our babies_long data frame currently looks like:
## # A tibble: 32 × 5
## id sex months weight length
## <int> <chr> <int> <dbl> <dbl>
## 1 1001 F 3 9 17
## 2 1001 F 6 13 18
## 3 1001 F 9 16 19
## 4 1001 F 12 17 21
## 5 1002 F 3 11 19
## 6 1002 F 6 16 21
## 7 1002 F 9 17 23
## 8 1002 F 12 20 23
## 9 1003 M 3 17 23
## 10 1003 M 6 20 27
## # ℹ 22 more rowsAs you probably guessed, we will use tidyr’s pivot_wider() function to restructure the data:
babies <- babies_long %>%
pivot_wider(
names_from = "months",
values_from = c("weight", "length")
) %>%
print()## # A tibble: 8 × 10
## id sex weight_3 weight_6 weight_9 weight_12 length_3 length_6 length_9 length_12
## <int> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1001 F 9 13 16 17 17 18 19 21
## 2 1002 F 11 16 17 20 19 21 23 23
## 3 1003 M 17 20 23 24 23 27 30 33
## 4 1004 F 16 18 21 22 20 22 24 26
## 5 1005 M 11 15 16 18 18 20 22 23
## 6 1006 M 17 21 25 26 22 26 28 30
## 7 1007 M 16 17 19 21 21 23 24 25
## 8 1008 F 15 16 18 19 18 19 23 24👆Here’s what we did above:
We used
tidyr’spivot_wider()function to restructure thebabies_longdata frame from person-period (long) to person-level (wide).You can type
?pivot_widerinto your R console to view the help documentation for this function and follow along with the explanation below.The first argument to the
pivot_wider()function is thedataargument. You should pass the name of the data frame you want to restructure to thedataargument. Above, we passed thebabies_longdata frame to thedataargument using a pipe operator.The third argument (we left the second argument at its default value) to the
pivot_wider()function is thenames_fromargument. You should pass this argument the name of a column, or columns, that exists in the data frame you passed to thedataargument. The column(s) you choose should contain values that you want to become column names in the wide data frame. That’s a little be confusing, and our example above is sort of subtle, so here is a more obvious example:
df <- tribble(
~id, ~measure, ~lbs_inches,
1, "weight", 9,
1, "length", 17,
2, "weight", 11,
2, "length", 19
) %>%
print()## # A tibble: 4 × 3
## id measure lbs_inches
## <dbl> <chr> <dbl>
## 1 1 weight 9
## 2 1 length 17
## 3 2 weight 11
## 4 2 length 19- In the data frame above, the values in the column named
measureare what we want to use as column names in our wide data frame. Therefore, we would pass"measure"to thenames_toargument ofpivot_wider():
## # A tibble: 2 × 3
## id weight length
## <dbl> <dbl> <dbl>
## 1 1 9 17
## 2 2 11 19Our
babiesexample was more subtle in the sense that the long version of our data frame already had columns namedweightandheight. However, we essentially wanted to change those column names by adding the values from the column namedmonthsto the current column names. So,weighttoweight_3, with the “3” coming from the columnmonths.The ninth argument (we left the fourth through eighth arguments at their default value) to the
pivot_wider()function is thevalues_fromargument. You should pass this argument the name of a column, or columns, that exists in the data frame you passed to thedataargument. The column(s) you choose should contain values for the new columns you want to create in the new wide data frame. In ourbabiesdata frame, we wanted to pull the values from theweightandlengthcolumns respectively.The combination of arguments (i.e.,
names_from = "months"andvalues_from = c("weight", "length")) that we passed topivot_wider()above essentially said, “make new columns from each combination of the values in the column namedmonthsand the column namesweightandlength. So,weight_3,weight_6, etc. Then, the values you put in each column should come from the intersection ofmonthandweight(for theweight_#) columns, ormonthandlength(for thelength_#) columns.
32.3.1 Why person-level?
Why might we want the babies data in this person-level format? Well, as we discussed above, there are a handful analytic techniques that require our data to be in this format. Unfortunately, those techniques are beyond the scope of this chapter. However, this person-level format is still useful for something as simple as calculating descriptive statistics about time-invariant variables. For example, the number of female and male babies in our data frame:
## # A tibble: 2 × 2
## sex n
## <chr> <int>
## 1 F 4
## 2 M 432.4 Pivoting summary statistics
What do I mean by pivoting “summary statistics?” Well, in all the examples above we were manipulating the actual data values that were gathered about our observational units – babies. However, the ultimate goal of doing this kind of data management is typically to analyze it. In other words, we can often learn more from collapsing our data into a relatively small number of summary statistics than we can by viewing the actual data values themselves. Having said that, not all ways of organizing our summary statistics are equally informative. Or, perhaps it’s more accurate to say that not all ways of organizing our summary statistics convey the information with equal efficiency.
There are probably a near-infinite number of possible examples of manipulating summary statistics that we could discuss. Obviously, I can’t cover them all. However, I will walk through two examples below that are intended to give you a feel for what we are talking about.
32.4.1 Pivoting summary statistics wide to long
Our first example is a pretty simple one. Let’s say that we are working with our person-level babies data frame. In this scenario, we want to calculate the mean and standard deviation of weight at the 3, 6, 9, and 12-month follow-up visits. We might do the calculations like this:
mean_weights <- babies %>%
summarise(
mean(weight_3),
sd(weight_3),
mean(weight_6),
sd(weight_6),
mean(weight_9),
sd(weight_9),
mean(weight_12),
sd(weight_12),
) %>%
print()## # A tibble: 1 × 8
## `mean(weight_3)` `sd(weight_3)` `mean(weight_6)` `sd(weight_6)` `mean(weight_9)` `sd(weight_9)` `mean(weight_12)` `sd(weight_12)`
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 14 3.16 17 2.62 19.4 3.34 20.9 3.04
🗒Side Note: This is not the most efficient way to do this analysis. We are only doing the analysis in this way to give us an excuse to use pivot_longer() to restructure some summary statistics.
By default, the mean and standard deviation are organized in a single row, side-by-side. One issue with organizing our results this way is that is that they don’t all fit on the screen at the same time. However, even if they did, it’s much more difficult for our brains to quickly scan the numbers and make comparisons across months when the summary statistics are organized this way than when they are stacked on top of each other. Take a look for yourself below:
mean_weights %>%
pivot_longer(
cols = everything(),
names_to = c(".value", "measure", "months"),
names_pattern = "(\\w+)\\((\\w+)_(\\d+)"
)## # A tibble: 4 × 4
## measure months mean sd
## <chr> <chr> <dbl> <dbl>
## 1 weight 3 14 3.16
## 2 weight 6 17 2.62
## 3 weight 9 19.4 3.34
## 4 weight 12 20.9 3.04👆Here’s what we did above:
We used
tidyr’spivot_longer()function to restructure our data frame of summary statistics from wide to long.The only new argument above is the
names_patternargument. You should pass a regular expression to thenames_patternargument. This regular expression will tellpivot_longer()how to break up the original column names and repurpose them for the new column names. The regular expression we used above is not intended to be the main lesson here. But, I’m sure that some of you will be curious about how it works, so I will try to briefly explain it below. In a way, this is how R interprets the regular expression above (feel free to skip if you aren’t interested):
## [,1] [,2] [,3] [,4]
## [1,] "mean(weight_3" "mean" "weight" "3"We haven’t used parentheses yet in our regular expressions, but they create something called “capturing groups.” Instead of saying, “look for this one thing in the character string,” we say “look for these groups of things in this character string.”
The first capture group in the regular expression is
(\\w+). This tells R to look for one or more word characters. The value that R grabs as part of this first capture group is given under the second result (i.e.,[,2]) above –"mean".Then, the regular expression tells R to look for a literal open parenthesis
\\(. However, this parenthesis is not included in a capture group. In this case, it’s really just used as landmark to tell R where the first capture group stops, and the second capture group starts.The second capture group in the regular expression is another
(\\w+). This again tells R to look for one or more word characters, but this time, R starts look for the word characters after the open parenthesis. The value that R grabs as part of the second capture group is given under the third result (i.e.,[,3]) above –"weight".Next, the regular expression tells R to look for a literal underscore
_. However, this underscore is not included in a capture group. In this case, it’s really just used as landmark to tell R where the second capture group stops, and the third capture group starts.The third and final capture group in the regular expression is
(\\d+). This tells R to look for one or more digits after the underscore. The value that R grabs as part of the third capture group is given under the third result (i.e.,[,4]) above –"3".Finally, R matches the values it grabs in each of the three capture groups with the three values passed to the
names_toargument, which are".value","measure", and"months". We already discussed the .value special value above. Similar to before, .value will create a new column for each unique value captured in the first capture group. In this case,meanandsd. Next, the values captured in the second capture group are assigned to a column namedmeasure. Finally, the values captured in the third capture group are assigned to a column namedmonths.
32.4.2 Pivoting summary statistics long to wide
This next example comes from an actual project I was involved with. As a part of this project, researchers asked the parents of elementary-aged children about series of sun protection behaviors. Below, I’m not simulating the data that was collected. Rather, I am simulating a small part of the results of one of the early descriptive analyses we conducted:
summary_stats <- tribble(
~period, ~behavior, ~value, ~n, ~n_total, ~percent,
"School Year Weekends", "Long sleeve shirt", "Never", 6, 78, 8,
"School Year Weekends", "Long sleeve shirt", "Seldom", 16, 78, 21,
"School Year Weekends", "Long sleeve shirt", "Sometimes", 33, 78, 42,
"School Year Weekends", "Long sleeve shirt", "Often", 17, 78, 22,
"School Year Weekends", "Long sleeve shirt", "Always", 6, 78, 8,
"School Year Weekends", "Long Pants", "Never", 5, 79, 6,
"School Year Weekends", "Long Pants", "Seldom", 15, 79, 19,
"School Year Weekends", "Long Pants", "Sometimes", 32, 79, 41,
"School Year Weekends", "Long Pants", "Often", 19, 79, 24,
"School Year Weekends", "Long Pants", "Always", 8, 79, 10,
"Summer", "Long sleeve shirt", "Never", 9, 80, 11,
"Summer", "Long sleeve shirt", "Seldom", 18, 80, 22,
"Summer", "Long sleeve shirt", "Sometimes", 31, 80, 39,
"Summer", "Long sleeve shirt", "Often", 14, 80, 18,
"Summer", "Long sleeve shirt", "Always", 8, 80, 10,
"Summer", "Long Pants", "Never", 7, 76, 9,
"Summer", "Long Pants", "Seldom", 16, 76, 21,
"Summer", "Long Pants", "Sometimes", 27, 76, 36,
"Summer", "Long Pants", "Often", 18, 76, 24,
"Summer", "Long Pants", "Always", 8, 76, 11
) %>%
print()## # A tibble: 20 × 6
## period behavior value n n_total percent
## <chr> <chr> <chr> <dbl> <dbl> <dbl>
## 1 School Year Weekends Long sleeve shirt Never 6 78 8
## 2 School Year Weekends Long sleeve shirt Seldom 16 78 21
## 3 School Year Weekends Long sleeve shirt Sometimes 33 78 42
## 4 School Year Weekends Long sleeve shirt Often 17 78 22
## 5 School Year Weekends Long sleeve shirt Always 6 78 8
## 6 School Year Weekends Long Pants Never 5 79 6
## 7 School Year Weekends Long Pants Seldom 15 79 19
## 8 School Year Weekends Long Pants Sometimes 32 79 41
## 9 School Year Weekends Long Pants Often 19 79 24
## 10 School Year Weekends Long Pants Always 8 79 10
## 11 Summer Long sleeve shirt Never 9 80 11
## 12 Summer Long sleeve shirt Seldom 18 80 22
## 13 Summer Long sleeve shirt Sometimes 31 80 39
## 14 Summer Long sleeve shirt Often 14 80 18
## 15 Summer Long sleeve shirt Always 8 80 10
## 16 Summer Long Pants Never 7 76 9
## 17 Summer Long Pants Seldom 16 76 21
## 18 Summer Long Pants Sometimes 27 76 36
## 19 Summer Long Pants Often 18 76 24
## 20 Summer Long Pants Always 8 76 11The
periodcolumn contains the time frame the researchers were asking the parents about. It can take the valuesSchool Year WeekendsorSummer.The
behaviorcolumn contains each of the specific behaviors that the researchers were interested in. Above,behaviortakes only the valuesLong sleeve shirtandLong Pants.The
valuecolumn contains the possible answer choices that parents could select from.The
ncolumn contains the number of parents who selected the response invaluefor the behavior inbehaviorand the time frame inperiod. For example,n= 6 in the first row indicates that six parents said that their child never wears long sleeve shirts on weekends during the school year.The
n_totalcolumn is the sum ofnfor each period/behavior combination.The
percentcolumn contains the percentage of parents who selected the response invaluefor the behavior inbehaviorand the time frame inperiod. For example,percent= 8 in the first row indicates that 8 percent of parents said that their child never wears long sleeve shirts on weekends during the school year.
These results are relatively difficult to scan and get a feel for. In particular, these researchers were interested in whether or not engagement in these protective behaviors differed by period. In other words, were kids more likely to wear long sleeve shirts on weekends during the school year than they were during the summer? It’s difficult to answer that quickly with the way the summary statistics above are organized. We can improve the interpretability of our results by combining n and percent into a single character string, and pivoting them wider so that the two periods are presented side-by-side:
summary_stats %>%
# Combine n and percent into a single character string
mutate(n_percent = paste0(n, " (", percent, ")")) %>%
# We no longer need n, n_total, percent
select(-n:-percent) %>%
pivot_wider(
names_from = "period",
values_from = "n_percent"
)## # A tibble: 10 × 4
## behavior value `School Year Weekends` Summer
## <chr> <chr> <chr> <chr>
## 1 Long sleeve shirt Never 6 (8) 9 (11)
## 2 Long sleeve shirt Seldom 16 (21) 18 (22)
## 3 Long sleeve shirt Sometimes 33 (42) 31 (39)
## 4 Long sleeve shirt Often 17 (22) 14 (18)
## 5 Long sleeve shirt Always 6 (8) 8 (10)
## 6 Long Pants Never 5 (6) 7 (9)
## 7 Long Pants Seldom 15 (19) 16 (21)
## 8 Long Pants Sometimes 32 (41) 27 (36)
## 9 Long Pants Often 19 (24) 18 (24)
## 10 Long Pants Always 8 (10) 8 (11)The layout of our summary statistics above is now much more compact. Further, it’s much easier to compare behaviors between the two time periods. For example, we can see that a slightly higher percentage of people (11%) reported that their child never wears a long sleeve shirt during the summer as compared to weekends during the school year (8%).
32.5 Tidy data
As I said above, the person-level (wide) and person-period (long) data structures are the traditional way of classifying how longitudinal (or repeated measures) data are organized. In reality, however, structuring data in a way that is most conducive to analysis is often more complicated than the examples above would lead you to believe. Simply thinking about data structure in terms of wide and long sometimes leaves us with an incomplete model for how to take many real-world data sets and prepare them for conducting analysis in an efficient way. In his seminal paper on the topic, Hadley Wickham, provides us with a set of guidelines for systematically (re)structuring our data in a way that is consistent, and generally optimized for analysis. He refers to this process as “tidying” our data, and to the resulting data frame as “tidy data”.8
🗒Side Note: If you are interested, you can download the entire article for free from the Journal of statistical Software here.
The three basic guidelines for tidy data are:
Each variable (i.e., measurement or characteristic about the observational unit) must have its own column.
Each observation (i.e. the people, places, or things we are interested in characterizing or comparing at a particular occasion) must have its own row.
Each value must have its own cell.
According to the tidy data philosophy, any data frame that does not conform to the guidelines above is considered “messy” data. In my opinion, it’s kind of hard to read the guidelines above and wrap your head around what tidy data is. I think it’s actually easier to get a feel for tidy data by looking at examples of data that are not tidy. Let’s go ahead and take a look at a few examples:
32.5.1 Each variable must have its own column
What does it mean for every variable to have its own column? Well, let’s say we interested the rate of neural tube defects by state. So, we pull some data from a government website that looks like this:
births_ntd <- tibble(
state = rep(c("CA", "FL", "TX"), each = 2),
outcome = rep(c("births", "neural tube defects"), 3),
count = c(454920, 318, 221542, 155, 378624, 265)
) %>%
print()## # A tibble: 6 × 3
## state outcome count
## <chr> <chr> <dbl>
## 1 CA births 454920
## 2 CA neural tube defects 318
## 3 FL births 221542
## 4 FL neural tube defects 155
## 5 TX births 378624
## 6 TX neural tube defects 265In this case, there is only one count column, but that column really contains two variables: the count of live births and the count of neural tube defects. Further, the outcome column doesn’t really contain “data.” In this case, the values stored in the outcome column are really data labels. We can tidy this data using the pivot_wider() function:
## # A tibble: 3 × 3
## state births `neural tube defects`
## <chr> <dbl> <dbl>
## 1 CA 454920 318
## 2 FL 221542 155
## 3 TX 378624 265Now, births and neural tube defects each have their own column. It might also be a good idea to remove the spaces from neural tube defects and make it clear that the values in each column are counts. But, I’m going to leave that to you.
Another common violation of the “each variable must have its own column” guideline is when column names contain data values. We already saw an example of this above. Our weight_ and length_ column names actually had time data embedded in them.
In the example below, each column name contains two data values (i.e., sex and year); however, neither variable currently has a column in the data:
births_sex <- tibble(
state = c("CA", "FL", "TX"),
f_2018 = c(222911, 108556, 185526),
m_2018 = c(232009, 112986, 193098)
) %>%
print()## # A tibble: 3 × 3
## state f_2018 m_2018
## <chr> <dbl> <dbl>
## 1 CA 222911 232009
## 2 FL 108556 112986
## 3 TX 185526 193098In this case, we can tidy the data by giving sex and year a column, and giving the other data values (i.e., count of live births) a more informative column name. We can do so with the pivot_longer() function:
births_sex %>%
pivot_longer(
cols = -state,
names_to = c("sex", "year"),
names_sep = "_",
values_to = "births"
)## # A tibble: 6 × 4
## state sex year births
## <chr> <chr> <chr> <dbl>
## 1 CA f 2018 222911
## 2 CA m 2018 232009
## 3 FL f 2018 108556
## 4 FL m 2018 112986
## 5 TX f 2018 185526
## 6 TX m 2018 19309832.5.2 Each observation must have its own row
Our person-level babies data frame above also violated this guideline.
## # A tibble: 8 × 10
## id sex weight_3 weight_6 weight_9 weight_12 length_3 length_6 length_9 length_12
## <int> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1001 F 9 13 16 17 17 18 19 21
## 2 1002 F 11 16 17 20 19 21 23 23
## 3 1003 M 17 20 23 24 23 27 30 33
## 4 1004 F 16 18 21 22 20 22 24 26
## 5 1005 M 11 15 16 18 18 20 22 23
## 6 1006 M 17 21 25 26 22 26 28 30
## 7 1007 M 16 17 19 21 21 23 24 25
## 8 1008 F 15 16 18 19 18 19 23 24Notice that each baby in this data has one row, but that each row actually contains four unique observations – at 3, 6, 9, and 12 months. As another example, let’s say that we’ve once again downloaded birth count data from a government website. This time, we are interested in investigating the absolute change in live births over the decade between 2010 and 2020. That data may look like this:
births_decade <- tibble(
state = c("CA", "FL", "TX"),
`2010` = c(409428, 199388, 340762),
`2020` = c(454920, 221542, 378624)
) %>%
print()## # A tibble: 3 × 3
## state `2010` `2020`
## <chr> <dbl> <dbl>
## 1 CA 409428 454920
## 2 FL 199388 221542
## 3 TX 340762 378624In this example, each state has a single row, but multiple observations. We can once again tidy this data using the pivot_longer() function:
## # A tibble: 6 × 3
## state year births
## <chr> <chr> <dbl>
## 1 CA 2010 409428
## 2 CA 2020 454920
## 3 FL 2010 199388
## 4 FL 2020 221542
## 5 TX 2010 340762
## 6 TX 2020 37862432.5.3 Each value must have its own cell
In my personal experience, violations of this guideline are rarer than violations of the first two guidelines. However, let’s imagine a study where we are monitoring the sleeping habits of newborn babies. Specifically, we are interested in the range of lengths of time they sleep. That data could be recorded the following way:
baby_sleep <- tibble(
id = c(1001, 1002, 1003),
sleep_range = c(".5-2", ".75-2.4", "1.1-3.8")
) %>%
print()## # A tibble: 3 × 2
## id sleep_range
## <dbl> <chr>
## 1 1001 .5-2
## 2 1002 .75-2.4
## 3 1003 1.1-3.8In this case, we will use a new function to tidy our data. We will use tidyr’s separate() function to spread these values out across two columns:
baby_sleep %>%
separate(
col = sleep_range,
into = c("min_hours", "max_hours"),
sep = "-",
convert = TRUE
)## # A tibble: 3 × 3
## id min_hours max_hours
## <dbl> <dbl> <dbl>
## 1 1001 0.5 2
## 2 1002 0.75 2.4
## 3 1003 1.1 3.8👆Here’s what we did above:
We used
tidyr’sseparate()function to tidy thebaby_sleepdata frame.You can type
?separateinto your R console to view the help documentation for this function and follow along with the explanation below.The first argument to the
separate()function is thedataargument. You should pass the name of the data frame you want to restructure to thedataargument. Above, we passed thebaby_sleepdata frame to thedataargument using a pipe operator.The second argument to the
separate()function is thecolargument. You should pass the name of the column contain the data values that you want to split up to thecolargument.The third argument to the
separate()function is theintoargument. You should pass theintoargument a character vector of column names you want to give the new columns that will be created when you break apart the values in thecolcolumn.The fourth argument to the
separate()function is thesepargument. You should pass thesepargument a character string that tellsseparate()what character separates the individual values in thecolcolumn.Finally, we passed the value
TRUEto theconvertargument. In doing so, we askedseparate()to coerce the values inmin_hoursandmax_hoursfrom character type to numeric type.
32.6 The complete() function
The final function we’re going to discuss in this chapter is tidyr’s complete() function. After we pivot data, we will sometimes notice “holes” in the data. This typically happens to me in the context of time data. When this happens, we can use the complete() function to fill-in the holes in our data.
This next example didn’t actually involve pivoting, but it did come from another actual project that I was involved with, and nicely demonstrates the importance of filling-in holes in the data. As a part of this project, researchers were interested in increasing the number of reports of elder mistreatment that were being made to Adult Protective Services (APS) by emergency medical technicians (EMTs) and paramedics. Each row in the raw data the researchers received from the emergency medical services provider represented a report to APS. Let’s say that the data from the week of October 28th, 2019 to November 3rd, 2019 looked something like this:
reports <- tibble(
date = as.Date(c(
"2019-10-29", "2019-10-29", "2019-10-30", "2019-11-02", "2019-11-02"
)),
emp_id = c(5123, 2224, 5153, 9876, 4030),
report_id = c("a8934", "af2as", "jzia3", "3293n", "dsf98")
) %>%
print()## # A tibble: 5 × 3
## date emp_id report_id
## <date> <dbl> <chr>
## 1 2019-10-29 5123 a8934
## 2 2019-10-29 2224 af2as
## 3 2019-10-30 5153 jzia3
## 4 2019-11-02 9876 3293n
## 5 2019-11-02 4030 dsf98Where:
dateis the date the report was made to APS.emp_idis a unique identifier for each EMT or paramedic.report_idis the unique identifier APS assigns to the incoming report.
Let’s say that the researchers were interested in calculating the average number of reports per day. We would first need to count the number of reports made each day:
## # A tibble: 3 × 2
## date n
## <date> <int>
## 1 2019-10-29 2
## 2 2019-10-30 1
## 3 2019-11-02 2Next, we might naively go ahead and calculate the mean of n like this:
## # A tibble: 1 × 1
## mean_reports_per_day
## <dbl>
## 1 1.67And conclude that the mean number of reports made per day was 1.67. However, there is a problem with this strategy. Our study period wasn’t three days long. It was seven days long (i.e., October 28th, 2019 to November 3rd, 2019). Because there weren’t any reports made on 2019-10-28, 2019-10-31, 2019-11-01, or 2019-11-03 they don’t exist in our count data. But, their absence doesn’t represent a missing or unknown value. Their absence represents zero reports being made on that day. We need to explicitly encode that information in our count data if we want to accurately calculate the mean number of reports per day. In this tiny little simulated data frame, it’s trivial to do this calculation manually. However, the real data set was collected over a three-year period. That’s over 1,000 days that would have to be manually accounted for.
Luckily, we can use tidyr’s complete() function, along with the seq.Date() function we learned in the chapter on working with date variables, to fill-in the holes in our count data in an automated way:
reports %>%
count(date) %>%
complete(
date = seq.Date(
from = as.Date("2019-10-28"),
to = as.Date("2019-11-03"),
by = "days"
)
)## # A tibble: 7 × 2
## date n
## <date> <int>
## 1 2019-10-28 NA
## 2 2019-10-29 2
## 3 2019-10-30 1
## 4 2019-10-31 NA
## 5 2019-11-01 NA
## 6 2019-11-02 2
## 7 2019-11-03 NA👆Here’s what we did above:
We used
tidyr’scomplete()function to fill-in the holes in the dates between 2019-10-28 and 2019-11-03.You can type
?completeinto your R console to view the help documentation for this function and follow along with the explanation below.The first argument to the
complete()function is thedataargument. You should pass the name of the data frame that contains the column you want to fill-in to thedataargument. Above, we passed thereportsdata frame to thedataargument using a pipe operator.The second argument to the
complete()function is the...argument. This is where you tell thecomplete()function which column you want to fill-in, or expand, and give it instructions for doing so. Above, we askedcomplete()to make sure that each day between 2019-10-28 and 2019-11-03 was included in ourdatecolumn. We did so by askingcomplete()to set the date column equal to the returned values from theseq.Date()function.
Notice that all the days during our period of interest are now included in our count data. However, by default, the value for each new row of the n column is set to NA. But, as we already discussed, n isn’t missing for those days, it’s zero. We can change those values from NA to zero by adjusting the value we pass to the fill argument. We’ll do that next:
reports %>%
count(date) %>%
complete(
date = seq.Date(
from = as.Date("2019-10-28"),
to = as.Date("2019-11-03"),
by = "days"
),
fill = list(n = 0)
)## # A tibble: 7 × 2
## date n
## <date> <int>
## 1 2019-10-28 0
## 2 2019-10-29 2
## 3 2019-10-30 1
## 4 2019-10-31 0
## 5 2019-11-01 0
## 6 2019-11-02 2
## 7 2019-11-03 0Now, we can finally calculate the correct value for mean number of reports made per day during the week of October 28th, 2019 to November 3rd, 2019:
reports %>%
count(date) %>%
complete(
date = seq.Date(
from = as.Date("2019-10-28"),
to = as.Date("2019-11-03"),
by = "days"
),
fill = list(n = 0)
) %>%
summarise(mean_reports_per_day = mean(n))## # A tibble: 1 × 1
## mean_reports_per_day
## <dbl>
## 1 0.714That concludes the chapter on restructuring data. For now, it also concludes the part of this book devoted to the basics of data management. At this point, you should have the tools you need to tackle the majority of the common data management tasks that you will come across. Further, there’s a good chance that the packages we’ve used in this part of the book will contain a solution for the remaining data management challenges that we haven’t explicitly covered. In the next part of the book, we will dive into repeated operations.